Počítačové zadanie: Strojovo orientované jazyky : Zadanie č.18
Skryť detaily | Obľúbený- Kvalita:83,1 %
- Typ:Počítačové zadanie
- Univerzita:Technická univerzita v Košiciach
- Fakulta:Fakulta elektrotechniky a informatiky
- Kategória:Technika
- Podkategória:Programovanie
- Predmet:Strojovo orientované jazyky
- Dokumentácia:Stiahni
- Ročník:2. ročník
- Rozsah A4:6 strán
- Zobrazené:2 311 x
- Stiahnuté:5 x
- Veľkosť:0,1 MB
- Formát a prípona:Archív súborov (.zip)
- Jazyk:slovenský
- ID projektu:16
- Posledna úprava:29.01.2015


1. Text zadania:
Načítajte z klávesnice reťazec znakov ukončený znakom "nového riadku". Nech slovo je postupnosť znakov medzi dvoma znakmi "medzera". Určte počet slov obsahujúcich reťazec UNIX. Počet vytlačte osmičkovo.
2. Dodefinovanie zadania:
Riešenie bude počítať počet výskytov do 16 bitového registra ale platných je len 15 bitov.
3. Analýza riešenia:
Dané riešenie má zmysel len ak je počet slov s výskytom UNIX menší ako 215 inak pretečie daný register do ktorého počítame počet výskytov. Riešenie má brať do úvahy slovo len raz aj keď sa v ňom vyskytuje UNIX viac krat.
4. Návrh algoritmu:
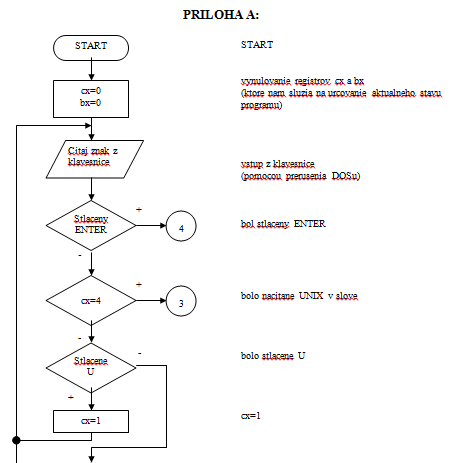
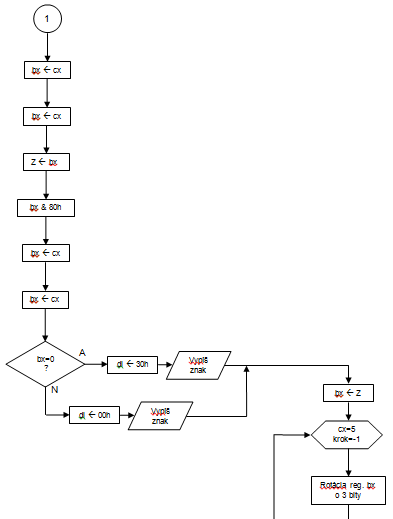
Vid. PRILOHA A
5. Popis algoritmu:
Určovanie počtu výskytov slov s reťazcom UNIX je založený na sekvenčnom zisťovaní či bolo stlačené U, potom sa zisťuje stlačenie ďalších znakov z hľadaného reťazca. Ak je medzi jednotlivými znakmi reťazca nejaký iný znak tak opäť čakáme na znak U. Keď je stlačený ENTER tak zistime či ešte v poslednom slove sa nevyskytuje hľadaný reťazec. Potom nasleduje konvertovanie počtu výskytov z HEX kódu do OCT kódu. Ktorého princíp je v tom, že rotáciou daného registra vždy dostaneme na prvé miesto 3-bity ktoré potom zobrazíme.
6. Popis funkcií a údajových štruktúr:
REGISTRE:
ax - pomocný register pri volaní prerušení
bx - register na počítanie počtu výskytov slov z reťazcom UNIX
cx - pomocný register pre cykly a pre stav načítavania reťazca UNIX
dx - pomocný register pri konverzií z HEX do OCT
Načítajte z klávesnice reťazec znakov ukončený znakom "nového riadku". Nech slovo je postupnosť znakov medzi dvoma znakmi "medzera". Určte počet slov obsahujúcich reťazec UNIX. Počet vytlačte osmičkovo.
2. Dodefinovanie zadania:
Riešenie bude počítať počet výskytov do 16 bitového registra ale platných je len 15 bitov.
3. Analýza riešenia:
Dané riešenie má zmysel len ak je počet slov s výskytom UNIX menší ako 215 inak pretečie daný register do ktorého počítame počet výskytov. Riešenie má brať do úvahy slovo len raz aj keď sa v ňom vyskytuje UNIX viac krat.
4. Návrh algoritmu:
Vid. PRILOHA A
5. Popis algoritmu:
Určovanie počtu výskytov slov s reťazcom UNIX je založený na sekvenčnom zisťovaní či bolo stlačené U, potom sa zisťuje stlačenie ďalších znakov z hľadaného reťazca. Ak je medzi jednotlivými znakmi reťazca nejaký iný znak tak opäť čakáme na znak U. Keď je stlačený ENTER tak zistime či ešte v poslednom slove sa nevyskytuje hľadaný reťazec. Potom nasleduje konvertovanie počtu výskytov z HEX kódu do OCT kódu. Ktorého princíp je v tom, že rotáciou daného registra vždy dostaneme na prvé miesto 3-bity ktoré potom zobrazíme.
6. Popis funkcií a údajových štruktúr:
REGISTRE:
ax - pomocný register pri volaní prerušení
bx - register na počítanie počtu výskytov slov z reťazcom UNIX
cx - pomocný register pre cykly a pre stav načítavania reťazca UNIX
dx - pomocný register pri konverzií z HEX do OCT