Semestrálna práca: Rozhodovacie stromy (algoritmus C5.0)
Skryť detaily | Obľúbený- Kvalita:90,3 %
- Typ:Semestrálna práca
- Univerzita:Technická univerzita v Košiciach
- Fakulta:Fakulta elektrotechniky a informatiky
- Kategória:Technika
- Podkategória:Informatika
- Predmet:Objavovanie znalosti
- Študijný program:Hospodárska informatika
- Autor:monika.cinkanicova
- Ročník:4. ročník
- Rozsah A4:57 strán
- Zobrazené:3 050 x
- Stiahnuté:7 x
- Veľkosť:3,9 MB
- Formát a prípona:MS Office Word (.docx)
- Jazyk:slovenský
- ID projektu:42383
- Posledna úprava:25.08.2013

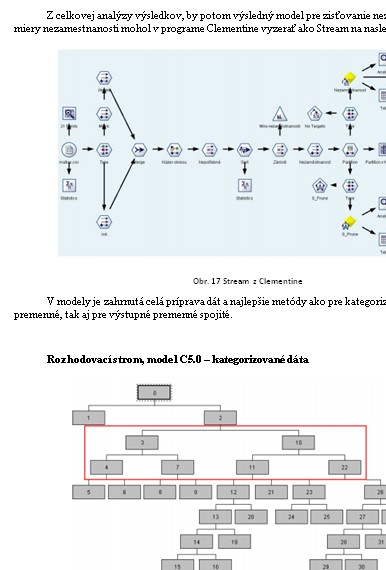


V práci sú podrobne popísane rozhodovacie stromy. Zvolené dáta sú spracované pomocou programu Clementine, ktorý slúži na dolovanie v dátach. Na toto dolovanie je využitý algoritmus C5.0.
Obsahom projektu je popísať rozhodovacie stromy a pomocou zadaného algoritmu dolovať požadované dáta zo zvolenej množiny dát. Projekt tvorí niekoľko kapitol. Ide o nasledujúce: Rozhodovacie stromy, Modely rozhodovacích stromov, Aplikačné príklady, Popis dát, ktoré boli pridelené na zadanie, Popis predspracovania dát, Interpretácia výsledkov.
1 Rozhodovacie stromy
Rozhodovacie stromy sú silným nástrojom používaným na klasifikáciu a predikciu. Tiež je možné rozhodovacie stromy definovať ako štruktúru na predikovanie cieľového atribútu za pomoci jednoduchých rozhodovacích pravidiel. Ako už bolo spomenuté, sú technikou aj klasifikácie aj predikcie. Ďalšou definíciou rozhodovacích stromov je definícia, že rozhodovací strom je klasifikátor so stromovou štruktúrou. Vnútorné uzly sa nazývajú rozhodovacie. Aby bolo možné zostaviť rozhodovacie stromy je nutné využiť testovaciu množinu dát. Tie špecifikujú test vykonaný nad atribútom inštancie, pričom každý možný výsledok testu je reprezentovaný jednou vetvou. List stromu indikuje hodnotu cieľovej vlastnosti príkladov (inštanciu triedy). Rozhodovací strom na zatriedenie príkladu začne v koreni stromu a prechádza cez jednotlivé uzly až k listu, ktorý poskytuje klasifikáciu inštancie. Rozhodovacie stromy prehľadne ilustrujú proces učenia. Venuje sa im veľká pozornosť najmä pre ich schopnosť pracovať s údajmi, ktoré nie sú úplné alebo sa v nich vyskytujú chyby. Algoritmy, pomocou ktorých sa dajú generovať rozhodovacie stromy sú založené na princípe budovania stromov zhora nadol. Používajú sa v znalostných systémoch na automatické generovanie báz znalostí, v objavovaní znalostí a ďalších oblastiach. Tiež sa dajú použiť na identifikáciu segmentov s požadovaným chovaním napr. pri modelovaní odozvy, oproti regresií majú však výhodu v schopnosti detekovať nelineárne závislosti. Cieľom tejto metódy je sekvenčne rozdeliť údaje do rozdielnych skupín alebo vetiev, aby maximalizovali rozdiely v údajoch závislej premennej.
Obsahom projektu je popísať rozhodovacie stromy a pomocou zadaného algoritmu dolovať požadované dáta zo zvolenej množiny dát. Projekt tvorí niekoľko kapitol. Ide o nasledujúce: Rozhodovacie stromy, Modely rozhodovacích stromov, Aplikačné príklady, Popis dát, ktoré boli pridelené na zadanie, Popis predspracovania dát, Interpretácia výsledkov.
1 Rozhodovacie stromy
Rozhodovacie stromy sú silným nástrojom používaným na klasifikáciu a predikciu. Tiež je možné rozhodovacie stromy definovať ako štruktúru na predikovanie cieľového atribútu za pomoci jednoduchých rozhodovacích pravidiel. Ako už bolo spomenuté, sú technikou aj klasifikácie aj predikcie. Ďalšou definíciou rozhodovacích stromov je definícia, že rozhodovací strom je klasifikátor so stromovou štruktúrou. Vnútorné uzly sa nazývajú rozhodovacie. Aby bolo možné zostaviť rozhodovacie stromy je nutné využiť testovaciu množinu dát. Tie špecifikujú test vykonaný nad atribútom inštancie, pričom každý možný výsledok testu je reprezentovaný jednou vetvou. List stromu indikuje hodnotu cieľovej vlastnosti príkladov (inštanciu triedy). Rozhodovací strom na zatriedenie príkladu začne v koreni stromu a prechádza cez jednotlivé uzly až k listu, ktorý poskytuje klasifikáciu inštancie. Rozhodovacie stromy prehľadne ilustrujú proces učenia. Venuje sa im veľká pozornosť najmä pre ich schopnosť pracovať s údajmi, ktoré nie sú úplné alebo sa v nich vyskytujú chyby. Algoritmy, pomocou ktorých sa dajú generovať rozhodovacie stromy sú založené na princípe budovania stromov zhora nadol. Používajú sa v znalostných systémoch na automatické generovanie báz znalostí, v objavovaní znalostí a ďalších oblastiach. Tiež sa dajú použiť na identifikáciu segmentov s požadovaným chovaním napr. pri modelovaní odozvy, oproti regresií majú však výhodu v schopnosti detekovať nelineárne závislosti. Cieľom tejto metódy je sekvenčne rozdeliť údaje do rozdielnych skupín alebo vetiev, aby maximalizovali rozdiely v údajoch závislej premennej.